
Émilie Feral — 26 de outubro de 2021
Malloc - Crónica de uma morte anunciada
A gestão da memória é um ponto crítico num sistema incorporado. Este artigo explica as razões que nos levaram a dispensar o malloc, um termo usado em programação para designar o método padrão de alocação dinâmica da memória da linguagem de programação C ou C++.
Alocação dinâmica: qual é a necessidade em Epsilon?
Quando um cálculo é inserido, este é analisado e armazenado como uma árvore.
Assim, 1+2*π é armazenado como:

Obviamente, o tamanho destas árvores varia, dependendo da expressão introduzida. Precisamos, portanto, de um espaço de memória no qual possamos armazenar objetos cujo tamanho não seja conhecido antecipadamente. Normalmente, um espaço de memória a que se chama heap serve como espaço de armazenamento para todos os objetos cujo tamanho é apenas conhecido à medida que ocorre a sua execução.
Em C, a função malloc da biblioteca padrão permite reservar uma área de memória de um determinado tamanho durante a execução: esta é uma alocação dinâmica. Até à versão do nosso software Epsilon 1.7, era assim que as expressões matemáticas eram armazenadas na calculadora: cada nó da árvore era atribuído algures na pilha e guardava ponteiros para os seus filhos.
No exemplo acima, o nó + manteve dois endereços indicando onde os seus filhos 1 e x estavam armazenados.
Porquê mudar de estratégia?
Este método tem algumas limitações:
- Fragmentação da memória: o espaço de memória do heap pode não conter espaço consecutivo suficiente para um novo nó, mas ter ainda espaço vazio (não consecutivo) para armazenar o objeto.

A alocação de espaço a laranja falha quando haveria memória suficiente se esta não estivesse fragmentada…
- Além disso, o algoritmo
mallocfoi projetado para alocar com sucesso uma área de memória num máximo de casos possíveis para todas as utilizações. Ao utilizar esta função genérica, não tiramos partido de algumas especificidades das expressões que atribuímos, por exemplo:- Uma característica atribuída ao tamanho da área; limitada entre o menor nó e o maior nó utilizados.
- Dois nós alocados consecutivamente podem ser utilizados e destruídos ao mesmo tempo (se pertencerem à mesma árvore, por exemplo).
A propósito, o uso do heap requer um certo rigor por parte do programador:
- Assim que um objeto é alocado ao heap, deve considerar-se a possibilidade de que a alocação de memória pode falhar. Isto obriga a que o programador faça uma gestão manual deste caso ao longo de todo o código.
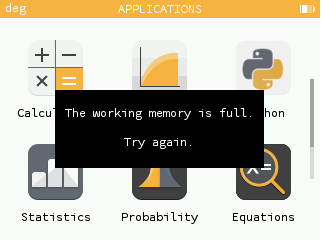
- Devemos evitar vazamentos da memória: quando nos esquecemos de apagar um objeto alocado ao heap, cada vez que executamos esse pedaço de código, enchemos um pouco mais o heap de novo, sem nunca o limpar totalmente. O software acabará inevitavelmente por falhar (ou ter erros contínuos devido à falta de memória) quando o heap estiver cheio.
Como armazenar expressões sem malloc?
Por todas estas razões, na atualização 1.8 do Epsilon, o nosso software, decidimos deixar de usar malloc. Tivemos de escolher um novo método para armazenar expressões que se ajustasse melhor aos requisitos do nosso módulo de matemática.
Reservámos uma área da memória de 32kb utilizada como buffer para armazenar as expressões: é o nosso Pool. Para evitar a fragmentação da memória, as árvores de expressão são aí armazenadas consecutivamente. Além disso, se um nó tem filhos, estas são as árvores que o seguem diretamente no Pool. Isto evita, entre s coisas, ter de manter as indicações para os seus filhos num nó.
Alguns tipos de nós têm um tamanho variável, dependendo dos seus dados: por exemplo, um nó que represente um número inteiro será maior quanto mais dígitos tiver na base 2^32.
Como o Pool não tem área de memória vazia entre dois nós, o local onde um nó é armazenado ‘escorrega’ quando o nó anterior é excluído. Portanto, já não é possível usar uma seta para definir o nó. É por isso que cada nó tem um identificador único definido arbitrariamente.

Pool contendo 1+2π
Um novo modelo, novas limitações
Na prática, para aceder a um nó com este identificador, tem de se navegar pelo pool até o encontrar. Além disso, a modificação de uma expressão traduz a memória de todo o pool a partir do nó modificado. Os processos de leitura e escrita são, portanto, mais lentos do que se fosse utilizado um malloc (por serem lineares). Como muitas vezes acontece na ciência da computação, trata-se de um compromisso entre poupar tempo ou espaço na memória.
No entanto, para evitar uma regressão significativa no tempo de computação, o nosso pool está associado a uma cache que recorda a associação entre o nó e o endereço da memória. Esta cache é utilizada cada vez que um nó é modificado.
| id | adresses |
|---|---|
| + | 0x0232 |
| 1 | 0x023d |
| × | 0x023f |
| 2 | 0x0242 |
| π | 0x0247 |
| cos | 0x024a |
| + | 0x084d |
Finalmente, a atualização 1.8 otimizou o uso da memória e permitiu aproveitá-la para gerir o caso em que demasiadas expressões foram alocadas.
Links para os arquivos que implementam o Pool de expressões:
- A classe de nós armazenados no Pool : tree_node.h e tree_node.cpp.
- A classe dos identificadores associados com os nós: tree_handle.h et tree_handle.cpp
- A classe do Pool : tree_pool.h et tree_pool.cpp.
Émilie Feral — Engenheira de Software
A Émilie estudou na École polytechnique* e juntou-se à NumWorks em julho de 2016 como programadora. Se a vossa calculadora pode fazer os cálculos mais loucos ou traçar uma curva a uma velocidade inigualável, é graças ao trabalho da Émilie! A Émilie faz maravilhas em C++ mas é campeã em muitos outros campos: basquetebol, ciclismo e até artes circenses!
*A École polytechnique - Escola Politécnica de Paris - é uma das mais antigas escolas francesas. Fundada em 1794, mantém-se hoje como uma das mais prestigiadas escolas de engenharia, onde os alunos se centram no estudo da matemática, que associam à física, economia ou ciências da computação.

